Background
Cloud services use virtualization platforms to provide their services. These platforms use hypervisors to enable easier scalability of applications and higher system utilization by abstracting the underlying host resources. Unfortunately, these systems have an increased level of memory virtualization pressure, as hypervisors and guests keep separate page tables. The amount of address translation increases as the hypervisor-based systems involve two-dimensional page table walks. With the increased number of cores and big data sets, the conventional SRAM Translation Look-aside Buffers (TLBs), whose capacities are constrained by latency requirements, cannot hold all translations of page.
Invention description
This invention proposes to build very large Translation Look-aside Buffers (VL-TLBs) that may be stored in DRAM. While DRAM access is slow, only one access is required instead of up to 24 accesses required in many modern virtualized systems. Even if many of the 24 accesses may hit in the special paging structures, the aggregated cost of the many hits plus the overhead of the occasional misses from the paging structures still exceeds the cost of the one memory access to the VL-TLB. Additionally, it might be possible to implement the VL-TLB in emerging technologies such as the die-stacked DRAM with bandwidth and slight latency advantages.
The miss penalty of VL-TLB is high since page table walk has to wait until the latency of fetching an entry from DRAM. The hit/miss outcome can only be identified after entries are completely retried from L3 TLB. The penalty of an L3 TLB miss can be reduced using a predictor indexed by program counter and address offset.
Benefits/advantages
- Performance improvement of 12.5% when implemented in die-stacked DRAM
- Elimination of nearly all TLB misses in 8-core systems using VL-TLB of 64MB size
- Performance improvement of 10% when implemented in off-chip DRAM
- Very large TLB structure eliminates a large number of expensive page table walks.
- Low overhead TLB locations predictor make L3 TLB a feasible option.
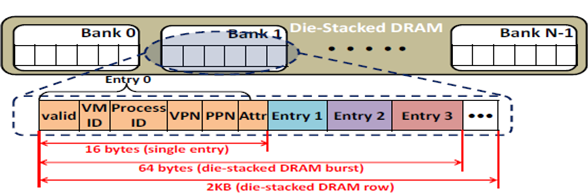
The figure illustrates a single channel of a typical die-stacked DRAM with multiple banks in accordance with an embodiment of the present invention.